Here's my backup strategy for my 300GB Picturelife account
Picturelife has done it again: They’ve just released the latest version of their service on mobile and it’s even better than before. The price plans have had a total re-jig and now for $15/month, you’ll get unlimited storage for all your photos and video.
Picturelife’s back-end data storage parter is Amazon S3.
Amazon is rock solid.
Right?
Yes.
Here’s some data via Stack Overflow from Amazon themselves:
Q: How durable is Amazon S3?
Amazon S3 is designed to provide 99.999999999% durability of objects over a given year. This durability level corresponds to an average annual expected loss of 0.000000001% of objects. For example, if you store 10,000 objects with Amazon S3, you can on average expect to incur a loss of a single object once every 10,000,000 years. In addition, Amazon S3 is designed to sustain the concurrent loss of data in two facilities.
Q: How is Amazon S3 designed to achieve 99.999999999% durability?
Amazon S3 redundantly stores your objects on multiple devices across multiple facilities in an Amazon S3 Region. The service is designed to sustain concurrent device failures by quickly detecting and repairing any lost redundancy. When processing a request to store data, the service will redundantly store your object across multiple facilities before returning SUCCESS. Amazon S3 also regularly verifies the integrity of your data using checksums.
That durability is good enough for me, right?
Well.
No.
Backup the backup
And this is the crux of my problem with Picturelife.
I was happily going about my business sticking all of my photos and video on to the service and amassing a huge 300GB+ archive with them, loving every moment of the experience… until I did a 361 Degrees podcast with Ben and Rafe on the topic.
They thought I was nuts.
Their view is that I was utterly stupid to trust my most valuable data (photos and videos of the boys, family and so on) to an ‘unknown party’, even if that party — Picturelife — were using something as reliable as Amazon.
Ben and Rafe set about quoting the backup maxims. You know, things like, make sure you’ve got a local copy; make sure you’ve got two copies in two different locations on two different media sets. Yada yada.
I ignored them for a little while. I did break out into mental sweats whenever I thought about it, though.
What if some hacker managed to crack Picturelife and delete half their data structures — taking my 300GB with it?
Well, I’m pretty sure (although I haven’t confirmed) that Picturelife will have versioning turned on with their S3 storage, meaning that, theoretically, you can’t actually delete anything. You’ve always got an older copy.
Again, theoretically, that can be switched off (or, more accurately, paused) and hackers could have fun with that too.
I’m the weak point
The underpinning point: Amazon isn’t the problem, it’s other ‘actors’ that could mess with my data — not least someone cracking my super-hyper-crazy Picturelife password (thanks to Dashlane) and proceeding to delete every single file on my account using my credentials.
Again, one would hope that Picturelife support could, using versioning, be able to recover my data? Right? Probably.
But I don’t know. And Picturelife has not hitherto dealt with this level of worry.
I think it’s important they do, at some point.
One key thing they’ve offered from more or less day one is the ability to opt to use your OWN Amazon S3 ‘bucket’ to store your Picturelife account. If you do that, then they won’t actually bill you (given that you assume the bandwidth and hosting costs yourself).
A little while ago I rolled up my sleeves and setup my own bucket and transferred my 300Gb across.
Great.
Now my pictures and videos are stored in my own bucket. The service level is exactly the same. I can still use the app and web service as normal. I see no practical difference day-to-day.
However I can login with an S3 ‘file browser’ and I can verify that my files are there. This is the equivalent of a data centre manager who simply won’t swap to virtualisation, who insists on being able to touch his or her servers physically.
This week, however, I decided to change that.
Programming my own backup script
I flexed my LAMP (“Linux Apache MySQL PHP”) skillz. I flicked up a Rackspace Cloud server on CentOS, installed AMP, found the Amazon S3 class on Github and proceeded to see if I could work out a way of downloading each of my files sequentially.
You see, I’d used an S3 file browser to check my bucket and found 100,000+ files there. Picturelife takes your photo and makes two additional copies as you might expect — one as a quick ’tile’ shot and another ‘larger’ shot, as well as the original. Useful for caching purposes. You don’t really want to download an 8mb photo if you’re just swiping through it.
So I have about 33,000 photos and videos. Which equates to about 100k files. The file browser was having trouble parsing the 100k file list.
That led me to programming my own download script.
Which I duly created.
I’m rather proud of myself, dear reader. I flexed the LAMP skillz and boom, data arrived! I started programming at 11pm and by 2am I went to bed and left my scripts to work downloading the 33,000 files to an external drive connected to my MacBook. Thank you BT Infinity.
24 hours passed and I had retrieved everything.
I felt complete inside.
I felt whole.
I had a 300gb copy on my Rackspace cloud server (which I’ve since imaged/backed-up and shut down for the moment) and I’ve also got a copy on my USB drive.
The bad news is that the files I’ve downloaded have been stripped of the file creation dates. That was a bummer. That data is obviously stored elsewhere in the bucket (or on the Picturelife main servers).
Still: I do actually have the raw photos and videos. That’s the important bit, right? So if everything goes to pot, I have got a backup.
I shouldn’t have had to do this
Arguably most people don’t obsess at this level. I blame Ben and Rafe. However they’re still in the dark ages. They are still arsing around with Photostreams and iPhoto which, if you’ve got children like me (and you like taking photos and video) you will have noticed already that they are really poor.
Google’s Picasa does a nice job. It’s the same underpinning problem for me though: Control and management of data. I’m less worried about Picturelife and Amazon getting it wrong and more worried about some kind of stupid user-error on my part.
I would seriously love for Picturelife to offer an Amazon S3 bucket backup facility.
Or actually, I would really like to go back into the main Picturelife ‘account’ — instead of feeling as though I have to manage my own bucket — but with the premium option of being able to take a copy of my data and stick it somewhere else: Rackspace Cloud. Or Dropbox (even though they’re also using Amazon). Or something different.
I do not NOT NOT want to have to worry about managing my own picture and video data locally.
Local data management is an absolute joke — something that I think Ben and Rafe missed when they were lambasting me (rightly) about taking silly risks with valuable data. There’s no way at all I could rival Amazon or Picturelife’s reliability with my own infrastructure.
The issue I still face is redundant backup.
Just in case.
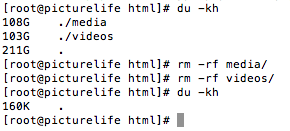
And here’s how easy it is, at least in my silly example, to dump my memories. I wanted to switch off my cloud server that I used for testing the backup script. I took a ‘backup’ or image of it whilst it contained the 200Gb data (i.e. just the original files, not all the ones created via Picturelife). I then wanted to create a ‘vanilla’ copy of the server config so I needed to dump the data. Here’s how I did it…
Where I am today
So the solution, temporarily at least (I’m looking at you, Nate Westheimer, CEO, Picturelife) is my own silly backup script that literally scrapes each file from the my Amazon bucket. (There are various rsync style options but I was looking for something I could directly tinker with myself)
Given the recent and welcome price plan changes for Picturelife ($15/month for unlimited is brilliant, and the ability to share that with 3 other family members is even better!) I wonder if the team will soon be looking for premium add-on options? Surely a backup option can’t be too far away?
In the meantime I am going to work on my Picturelife bucket scraper tool and my plan is to run it once a month. Or programme it properly so that it runs daily and sucks down the latest additional files. BUUUT all of a sudden my photo and video management costs have gone into the hundreds of dollars per month because I ideally need a cloud server to run this.
I should underline my fanatical approach to Picturelife, particularly for Nate and his colleagues if they’re reading. I’m a huge, huge fan. So much so that I continued to pay the $15/month fee, even when I moved to my own Amazon bucket (which, incidentally started costing me about $40/month!). I like the sound of the cut of Nate’s jib, as the phrase goes. Here’s Nate writing about the recent cloud hosting cuts.
If you haven’t tried Picturelife, do so. The company appears to be doing rather well and my wife and our family and friends are absolutely delighted with the service. It’s just me being anal about the double-backup thing.
Further background reading on the issue



